MACE 是一个嵌入式的键值存储引擎,已经断断续续的开发了近一年,目前来看应该不会有大的调整了。下面从几个方面介绍下这个引擎
背景
为什么要做这件事?
起因是当时在看 juicefs 代码,想着自己也写一个文件系统玩玩,于是便用 Rust 实现了一个叫做 JunkFS,它使用 Sled 作为文件系统的元数据存储(dentry、inode、superblock等),后来发现 Sled 的空间占用实在太大了,原本的想法是能不能改改 Sled,但发现它已经快两年多没有更新了,恰逢无意间在知乎上看到 LeanStore 的论文阅读,然后看到了张建大佬修改版的 LeanStore 结构更清晰了不说,代码也就不到3万行,于是有了自己造一个的想法
那为什么不直接使用 LeanStore 呢?
在看过 LeanStore 相关的论文和源码后,有一个点让人很难受:LeanStore 是基于 B+ 树的,也就是说它的 in-place-update,这就导致它的 Optimistic-Lock-Coupling 在遇到冲突时需要回退操作,在 LeanStore 中使用了 setjmp/longjmp 实现了一个叫做 JUMPMU 的东西,用来处理冲突时的回退。这个东西对我来说有两个致命的缺点:1. 复杂且极易出错,特别是在并发场景;2. 兼容性问题,能否迁移到Rust 和其他 OS ?除此之外,LeanStore 仅支持log buffer中的数据回滚,没有checkpoint,恢复也不完善,对了 Sled 的 transaction 也是很简陋,并且依赖手动或定时flush来保证数据完整
后来,看 Sled 的文档发现它使用的 Bw-Tree 的变体实现,于是读了相关的论文,后续又看到一个刚死不久的基于 Bw-Tree 的 PhotonDB,于是杂糅一下,借用 Sled 的 Tree,PhotonDB 提到的 Minimum Declining Cost,以及 LeanStore 的 Concurrency Control 就有了 MACE 的基本想法,当然作为一个外行,还需要阅读不少的资料
MACE
前面说了 MACE 是什么,这里说说它的特点:
- append-only 的结构,类似 LSM 树的写入性能,容易保证一致性,但是会产生垃圾需要清理
- 类似 B+ 树的查询性能,树节点动态大小,但是需要有一个驻留内存的 page table (实际上这点可以优化)
- scalable concurrency control,但是并发越高旧版本数据就留存越多
MACE的结构是分层的,最底层是和数据存储交互的,有 Buffer 和 GC 两块;往上就是索引数据结构的实现;再上层是事务相关实现;最上层就是对外的接口:put、update、get、seek、del
Buffer
叫这个名字可能不太恰当,因为和传统数据库的 Buffer Manager 不同,这里的 Buffer 并不负责页面的管理,而是一个资源的集合。其中包括一个内存分配器Arena的集合 Pool,一个基于 second-chance 算法的Cache,以及一个逻辑id到物理id映射管理的 Mapping
首先来讲 Arena
最早的实现中,Arena 就是一整块固定大小连续的内存,在初始化时预先分配,内部维护这一个 offset 和一个全局自增的文件 id,这样从其中分配的内存都有唯一的编号 pack_id(file_id, offset),每当 Arena 的offset 到达内存大小时就会转变为 sealed 状态,当不再被引用时会被完整的写入到数据文件,文件名称就包含 Arena 中的文件id
后来,发现Arena使用一整块固定大小的内存会有几个问题:1. 可能长时间被占用,而无法被及时刷盘,比如树的分支节点,频繁的被访问;2. 由于 append-only的性质, Arena 中包含大量的垃圾,一起刷盘造成严重的空间放大、浪费,并且影响GC
于是 Arena 就变成了一个 HashMap,其中存放 offset 和大小上限,以及一个真实的大小,分配的内存直接调用 alloc 完成,对应的 id 生产方式不变,只不过每个分配的内存自带引用计数,目的是将 Arena 的生命周期分成两个部分:可变的,不可变的。当可变的周期完成时,Arena 就可以被刷盘,但 Arena 在没有被重用前都可以被不可变的访问,这样就解决了第一个问题。另外在Arena可变期间产生的垃圾都会被标记为 TombStone,这样在刷盘过程中就可以跳过这些 TombStone 也就解决了第二个问题
接着来将 Cache
Cache 的作用很明确:控制MACE的内存占用。没错,这和通常的缓存的用来加速不同,MACE 中有一个 page table,其中存放的是树节点的逻辑 id (page_id)而真实的物理 id (addr) 是会经常变动的,因此 page table 作为一个映射,通过 page_id 找到 addr,并且 page table 使用了 SWIP 技术,addr 可以是内存地址也可以是节点在数据文件中的位置(addr),因此 page table 更像是用来加速的。但前面提到,page table 是必须要驻留在内存的,那么随着树节点的增多,那么内存占用必然增加,为了对内存占用做限制,因此有了 Cache
Cache 中记录了配置的最大内存占用,每当有新树节点分配时就会将 page_id 和它的内存占用大小记录到 Cache,当 Cache容量到达上限时,会随机挑选配置百分百的 Cold 状态的 page_id 进行淘汰,这个 page_id 会经由 page table 将内存指针转变为物理位置,并释放内存,在 Cache中的每个 page_id 会根据访问频率自动加热,初始时分支节点会比叶子节点更热,这样也就更不容易被淘汰
最后是 Mapping
Mapping 在垃圾回收和冷数据加载方面至关重要,其中最重要的又分为两个部分:1. logical_id 到 physical_id 的映射,2. MDC 状态记录
由于append-only的性质,随着写入的发生,数据文件会不断累积,因此需要在后台收集这些数据文件中活跃的数据转移到新的数据文件,这就会导致在 page table 中 page_id 的映射发生改变,原本对应的是 addr1 在数据转移之后就变成了 addr2,因此需要一个 logical_id 到 physical_id的转换层,在 page_table 中存放的是 logical_id,经过 Mapping 转换后得到 physical_id,在数据加载时发挥作用
而为了高效的转移数据,就必须考虑到后台任务的I/O资源和CPU资源的消耗,因此,在每次刷写数据文件时都会保留该文件的一部分信息到 Mapping 中,以便在GC任务中挑选到收益最高且消耗最少的数据文件进行数据转移
GC
关于 GC 的策略可以看看 这里 实现的细节可以看看 这里 这里不再详细介绍,目前的实现还很粗糙
Bw-Tree
MACE 中的实现基本算法和原版一致,不同点大约是在 delta 节点的组织和 SMO 的实现上
在 MACE 中原本也是基于链表的 delta,但查询性能很差,后来换成了 skiplist 但无法保证插入的原子性,后来又换成了 COW chunk,固定64给元素,但在大量并发时会导致溢出,而增大容量又无法利用局部性原理,最后和 Sled 一样使用了 COW B+ Tree 实现
另外由于 MACE 是支持事务的,并且针对大容量的键值,MACE 的树中的分支节点和叶子节点是不同的,分支节点只有 key 和 index,当然对于大容量的 key 可能是 remote 的,而叶子节点除了 key 和 value,还有 sibling ,sibling 则是MVCC中的版本存储,在叶子节点中相同的key的不同版本都存放在 sibling 中,sibling 本身的结构又和叶子节点一致,只不过不再包含sibling,但对于大容量的 value,仍然会作为remote存放在 sibling结构中,大约是这样
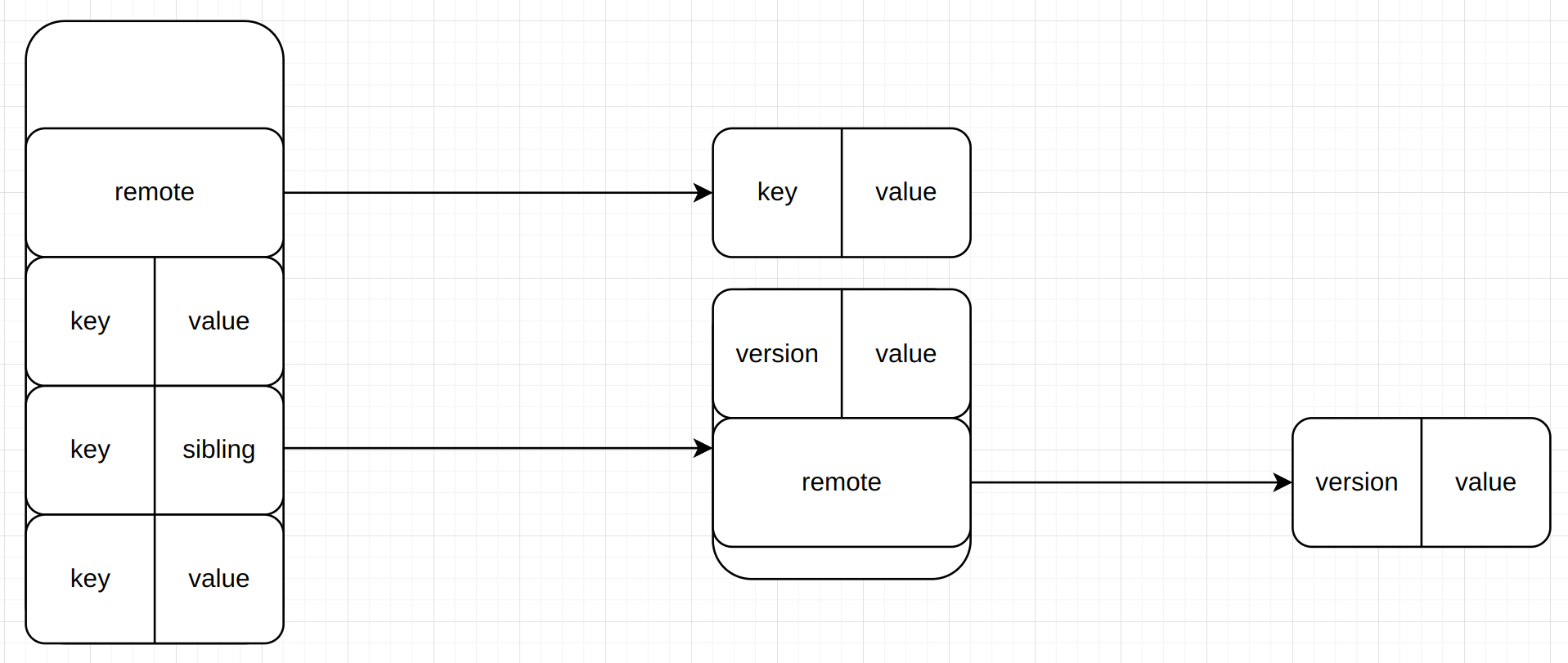
最后,值得一提的是 MACE 中树的节点是固定元素数量的,目的是更好的控制节点的分裂和合并,当然,由于 remote 的缘故,节点的实际大小仍然是不确定的
CC
详细介绍可以看 MVCC
回顾与展望
首先是编程语言的选择,实现使用了 Rust,发自内心来说对 Rust 并不感冒,甚至一开始文件系统的玩具也是用C++写的,但一想到测试还得选框架,万一遇到依赖还得自己维护,虽然有vcpkg这样的东西,但看到 LeanStore 的CMakeList就知道有多恶心,另一个重要的原因是跨平台要求。选择 Rust 主要看重了两个方面,一是 cargo 包管理,二是Rust 标准库对各个有完善的封装
其次是数据结构的选择,目前流行的键值数据库基本上都是基于 LSM Tree 的,但 LSM 有一个个人认为最大的缺陷就是范围扫描时需要涉及到多个 level 的 sst,另外还有 LMDB、boltdb 等少数使用 B+ 树实现,boltdb 是 LMDB的简化版,它们都使用 shadow page 技术实现,这就导致写入性能不够。而 Bw-Tree 则是写入和查询效率的一个平衡,除了微软的 Hekaton 后续有 ArkDB 基于 Bw-Tree,以及去年字节跳动和阿里巴巴都有基于 Bw-Tree 变体的实现
这些都是正确的选择,而错误的选择最严重的目前看来应该是照搬 LLAMA 论文中的那一套,不知道是它没有描述清楚还是个人的理解有问题,还是它只适合微软自己的事务引擎,前面提到 Arena 的实现已经变成了 hashmap 算是一个弥补
目前 MACE 应该算是完成了原型,对小键值来说吊打 RocksDB 还是没问题的,并且空间占用更小,但对于大键值来说还有不少的差距,反映在多个方面:1. 频繁的内存分配和拷贝;2. 缓存效率 3. GC 效率等。这些都是后续主要的工作所在,当然还有更多需要调整的地方,比如:插入失败的重试,目前是重头再来,这显然是不合理的;wisckey 需要吗?压缩需要吗?动态加载 page table 呢?等等…
最后提一句,MACE 的定位就是支持 SI 的平衡写入和查询效率的键值存储引擎,未来的路还很长
简单贴两个图
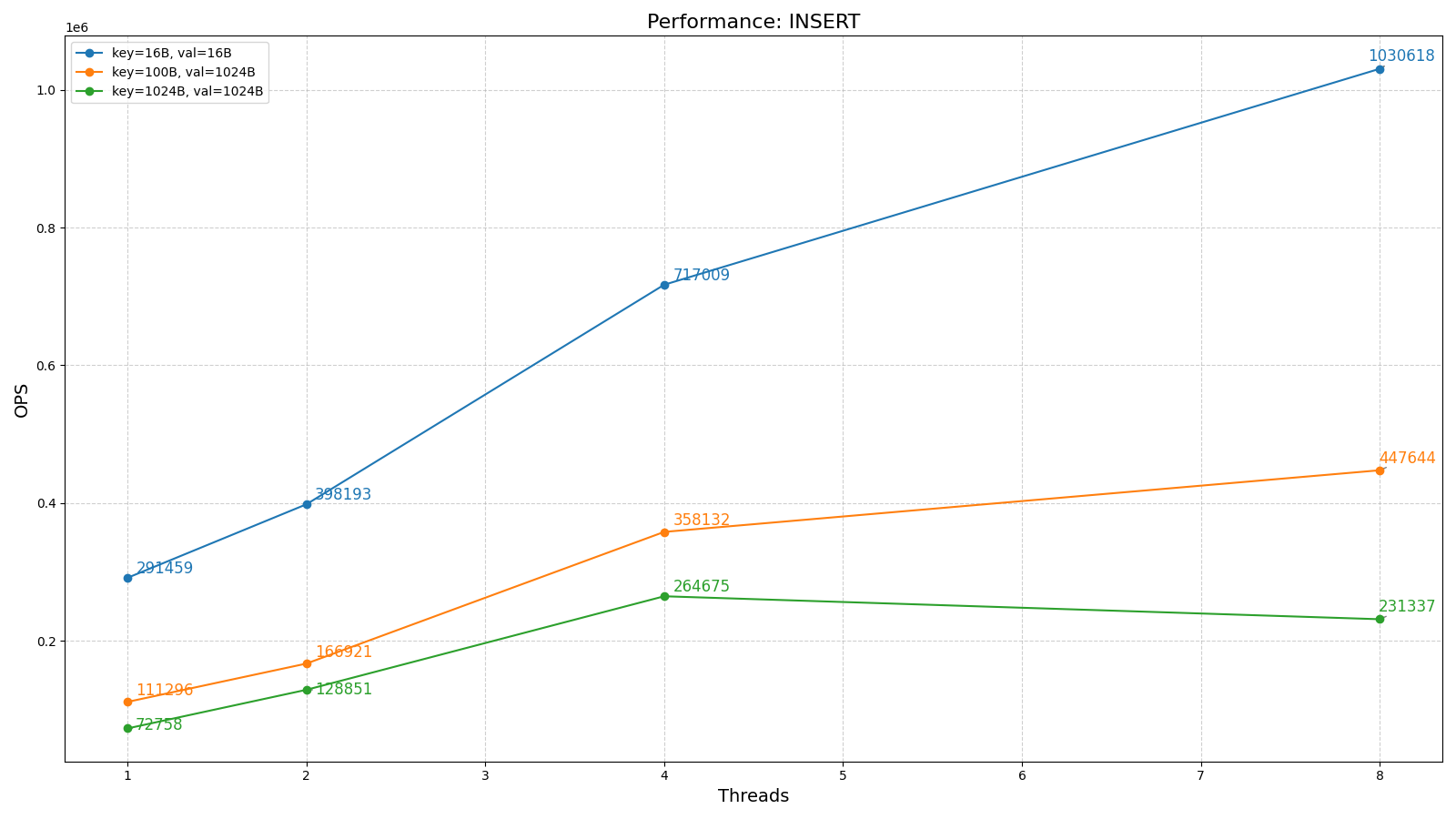
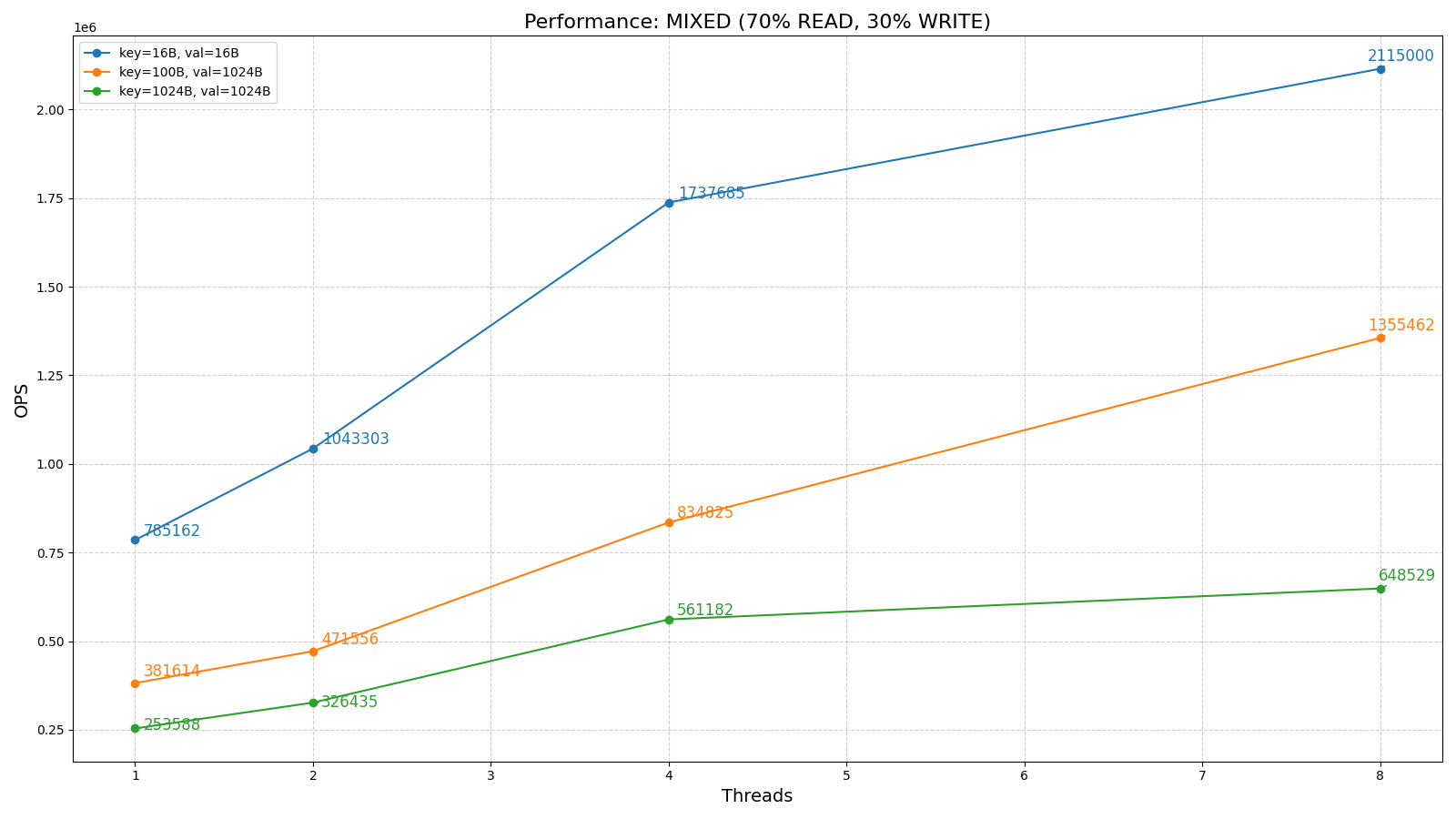
PS: Sled 最近又更新了,简单看了下,它可以看作是一个基于CAS的B+树和一个基于文件的slab系统的组合,真就是重写了