这是 SIGMOD 2025 上的一篇文章,又是TUM发的,主要讲针对SSD的日志刷盘和提交的优化,简单来讲就是日志自己刷盘,提交确认分组来搞(以及一些优化)
背景
日志刷盘的不同实现和它们的问题
中心化日志
经典的 ARIES 式的实现是:多个事务的日志都放在同一个 wal buffer 中,累计到一定数量(或一段延时)后一并刷盘。这在机械硬盘和较少的 CPU 核心时是问题不大的,但随着 CPU 核心的增多,单一的 wal buffer 带来极大的锁竞争开销,因此有了另一种实现
去中心化日志
既然一个 wal buffer 会有锁竞争的问题,那么每个 CPU 核心都绑定一个 wal buffer 不就行了。但这里没有考虑到事务提交的问题,例如 TX2 依赖于 TX1 虽然日志是刷盘了,但 TX2 必须等 TX1 提交后才能提交,因此有了另一种实现
组提交和去中心化日志
显然,这是前面两种的结合,日志是独立写到独立的 buffer 的,提交是统一检查的。但这也有另一个问题:提交确认仍然是瓶颈,尤其是在使用 SSD 时
这里简单解释一下实现的细节(其实就是 LeanStore 的实现):首先每个 worker 都有一段 log buffer,每次写日志都先记录到这个 buffer 中,后台的 group commit 线程会不断的遍历所有的 worker,第一遍是收集 buffer 写到日志文件,第二遍是检查能否提交,如果可以,那么会通知等待的 worker。前面说的“另一个问题”指的就是这个等待
观察和分析
首先是一个观察:在 SSD 上,小数据(4-16KB)的并发写入就像是免费的午餐(即但线程写4K和 8线程同时写 4K的时间是一样的),而大数据的写入则会带来很高的延时,所以一个想法就是:日志进行应该尽量的往“并行化的小数据写”靠近
然后是瓶颈分析,将事务的提交分成了4个阶段:1. 事务处理;2. 放入与提交队列排队;3. 日志刷盘;4. 提交确认的依赖检查。通过使用 LeanStore 来测试,发现这4个阶段中的延迟占比排序是:排队,提交确认,日志刷盘,事务执行。可以看到 “事务执行”其实是最不消耗时间的,下面就对其他3个来展开分析
刷盘延迟
在 Group Commit 中刷盘是由单线程处理的,每次处理的数据是所有 worker 的 buffer 中拿到的总和,也就是说 worker 越多每次刷盘的数据量就会越大,而根据前面的观察,在 SSD 上一次刷入的数据过多会导致延迟的上升
单线程的提交确认
同样的,在 Group Commit 中单线程的遍历所有预提交的事务,然后决定哪些事务是可提交的,这在 去中心化的 日志系统中会更糟糕,也是因为 worker 数量的影响
排队
在 去中心化日志 中排队等待的开销有两个来源,一是放到日志中等待被收集刷盘,二是刷盘后等待提交确认(这个前面那个相当于是观察点不同)。本质上就是因为耦合的设计带来的问题:Group Commit 既要负责刷盘又要复杂提交确认
自治提交
针对前面的3个问题,这里针对每个问题都给出一个优化
自治日志刷盘
很简单,每个 worker 自己刷盘,但因为使用了 O_DIRECT 要求4K对齐,如果只有少量数据的话会造成严重的写放大,因此每个 worker 自己准备一块 buffer 可配置大小,当 commit 产生后,检查日志大小是否达到配置,如果是就刷盘 然后通知其他worker已经准备好提交确认
自治提交确认
前面的问题是,单线程处理起来太慢了,那么这里就每个线程自己处理自己队列中的 commit,对于有依赖的情况,本事务需要收来来自其他事务的提交状态,来确认本事务是否可以提交,举例来说:
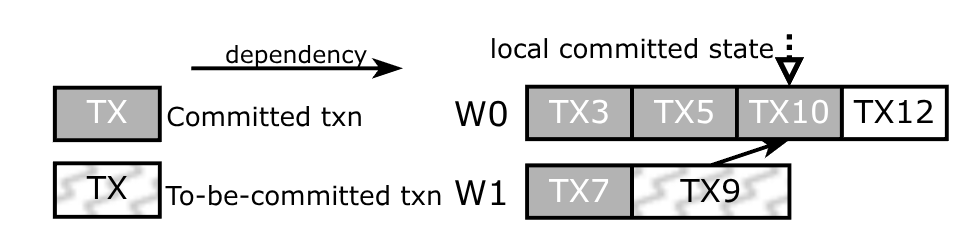
worker W0 的提交状态是 TX10,这意味着前面的 TX3、TX5 都已经提交了,假设 W1 中的 TX9 已经刷盘了,它依赖 TX10,那么 W1 就必须收到来自 W0 的提交状态,当发现 TX10 已经提交了,那么 W1 才能提交 TX9
当然,这又带来了另一个问题:如果 worker 很多,相互发消息(或者加锁共享)又会成为新的瓶颈。一个可能的解就是将这些 worker 分散到配置大小的“确认组”中
减轻排队开销
前面提到,造成这个问题的本质是耦合设计,因此只需要将日志刷盘和提交确认拆开来就可以做到日志刷盘和提交确认是交错执行的,这就减少了排队的开销
一点优化:日志窃取
前面提到“当日志到达配置大小后就刷盘”,那么如果很久都没有达到配置大小呢,特别是小的事务?比如配置大小是16K,而每个事务是160B,那么要累计100个事务才能刷盘,这显然会带来很高的延迟,虽然减少配置大小可以改善问题,但不能治本。另外强制刷盘的话虽然可以降低延迟,但会消耗SSD的IOPS,这会影响其他的 IO 操作
一个可能的解是:日志窃取。简单来讲就是一个 worker 在事务执行完后就遍历目标 worker (需要加锁)先将目标的事务拷贝到本地,然后通过 cas 修改目标的游标,这既可以确保同一个事务只会被一个worker窃取,同时也能告知其他 worker 它已经窃取了事务,最后就是简单的刷盘即可
问题是,窃取的策略呢,怎么知道要窃取哪个 worker 的日志呢?文章里面建议是共享LLC的核间进行窃取,这就得知道 CPU 核心的拓扑结构才行
除此之外,还有另外一个问题:多个worker窃取同一个worker的事务然后刷盘,这会导致刷盘的事务的顺序是乱的(即不是被窃取的worker中原本的顺序)。这个问题可以采用类似 parking-lot 的技术来解决(说实话没看懂它的例子)
低负载下的延迟管理
想象一下,有没有一种可能,当所有worker的日志加起来都达不到配置的大小,前面的所有工作都变得毫无意义。那怎么办呢?当然是强制提交了(这不就和前面的矛盾了🐎),即经过一段时间的 idle 就触发提交,不过是需要采样 idle 的时间计算评价 idle 时间然后和 rand(max_idle_time) 比较罢了
点评
以上就是主要的内容了,文章中后续就是一些优化,还有就是原来 LeanStore 中的实现搬过来讲讲
这篇文章总体来看一般,中个人认为最亮的点是那个SSD的观察,至于分析的瓶颈(这个瓶颈其实是LeanStore的)以及针对的优化大约只能留在实验室里面,例如:对于 append-only 的实现来说,如果是去中心化的日志实现,那么是不存在提交确认瓶颈的