自从去年年底开始使用 AI 辅助编码已经过去了快半年了,个人的感受是:AI 确实可以用了。但最近一个月来又有了新的感受:AI 还是太弱。
最近一个月在围绕一个workload(W4)做优化,95% 的随机更新 5% 的查询,在这个场景下 Mace 的 ops 只有 RocksDB 的 1⁄3 。一开始我定位到了在更新这个场景中 Mace 的 WAL 会写入 old value 和 new value 这样数据量就多了一倍,于是我告诉 AI 当前的问题是什么,让它设计方案解决这个问题,它很快给了我一个方案,当然这个方案被我否了,我在这个基础上修改了一下,update 的 old value 不再存放旧址,改成存放 old value 的 lsn 然后 AI 按照我修改的方案落地实现。结果是性能不升反降,AI 给的原因是:因为前台写入的数据量变少了,所以前台变快了,导致 arena 的消耗速度变快,进而导致刷盘的数据量增加,而刷盘数据量增加会导致 arena 的流转变慢,从而通过流控影响前台的写入
于是,我让它进行优化。它自己分析了更新的整个流程,觉得是流控太激进了,反复的修改流控代码,但结果毫无进展。我提示它,对于随机插入的场景,叶子节点很难进行 consolidate 基本上都是 delta,并且现在 arena 本身有一个 recycle 机制也没法利用起来,这才导致你说的 arena 消耗速度变快。于是 AI 转头去修改 flush 部分代码,它认为根因因该是 arena 的流转不够快。它把 flush 拆分成了可配置工作线程的模式,一下配置了8个线程进行文件的刷盘,将channel投递来的 arena 分配给工作线程并行的刷。这次却是有好转了,ops 能跑到 RocksDB 的 80% 了,AI 认为这条路是对的,继续在优化 flush 的调度。但始终没有进展,我观察发现,SSD 的负载已经非常高了,几乎必然会出现内部GC,于是我让它对比一下 Mace 和 RocksDB 总的刷盘量。AI 很快给了我结果,RocksDB 一共刷盘了 11 个 sst 总大小不到 3GB,Mace 一共刷盘了 119 个data文件总大小超过 10GB (加上 WAL 接近 30GB)
这下总算发现了问题所在,在 Mace 当前的实现中,整个 arena 是一起刷盘的,而 arena 中在随机插入的场景下有效载荷就非常的少,换句话说,arena 中绝大部分都是垃圾(插入首先会分配一个 delta page,delta page 在一个节点中会串联成一条链,当链的长度到达阈值时就会新分配一块连续的内存来将 delta page 重新组织成 sst 也就是 base page,当 base page 构建完成后,这些旧的 delta page就没用了,也就变成了垃圾),因此一个显而易见的优化方法就是:增大 arena,这样就可以通过 recycle 将 arena 中的垃圾去掉。但这不能治本,因为 wal checkpoint 还依赖于 arena 的flush,只有当数据持久化后 wal 才能被截断,并且正是因为有 recycle 机制的存在,需要根据 wal 的大小强制将 arena flush,因为如果是顺序插入的场景 recycle 会丢弃掉绝大多说的垃圾导致 arena 的大小上限迟迟不能触及,而 wal 却一直在增大
既然找到了问题所在,那么解决起来应该就轻松了吧。我有一个基本的想法,让 AI 给我整理一个方案,大致是:不再使用 arena 而是使用一个 Pool 来管理所有的 dirty page,并通过 dirty page set 来管理有更新的 pid,在刷盘时通过 dirty page set 中的 pid 遍历整个 delta chain 到 base page 把这个未持久化的部分刷盘即可,从而尽量避免将中间状态的 delta page 刷盘。方案我看了,没啥问题,于是我让 AI 按照方案实现,结果就是
根本跑不起来(它自己添加的一堆测试倒是过了),想起我之前认真的和AI讨论,我就觉得可笑
这个方案本身是没有问题的,但 AI 的实现偏离了方案。于是,我花了两周给 AI 擦屁股。我为什么不让 AI 自己修正呢?因为我发现:
- AI 生成的代码很难从全局的角度出发,它修复bug也很容易破坏不变量导致其他正常的功能出错,因此它会写大量的测试来给自己打气
- 大量的 AI 生成代码的注入,让我对项目的把控变弱了,无法做出正确的判断
在 AI 大量生成代码的情况下,人的决策反而是更重要的,因为 AI 不是 100% 可信的,你不知道它给你的对不对,你就无法保证质量。这对于前端页面可能还好,这里颜色不好看,那里没有对齐,也不是不能用,但对于一个存储引擎来说,一个比特的错误就是致命的!
在我花掉两周给AI擦屁股后,我才发现这个之前敲定的方案还有缺陷,方案中由于不会再刷盘中间态的垃圾,这就会导致多线程情况下(特别是 scan 场景)一些线程持有这 Node 的引用,其中的 remote/sibling 指针仍然会指向这中间态的垃圾,因此出现 dangling pointer 的情况。我决定再次相信 AI,因为花了两周擦屁股,我再次完全掌控了整个项目。这一次,AI 提出的方案是:将实现完全拆分成两套,在做 page checkpoint 前的所有操作都在内存中完成,在 page checkpoint 时,才将这些 dirty 的 node 冻结来刷盘。这一次,我让 AI 创建了一个 skill 专门防止执行偏离计划的问题产生,并且要求它每做完一个 phase 就等我 review。结果就是,又花掉了一周,但好在没有出现返工,不需要给它擦屁股。但这个方案也只是解决了生命周期的问题, W4 的性能仍然不达标
W4 的测试中 Mace 的 ops 并没有打赢 RocksDB,但已经变成了它的 80% 并且是在只有一个 flush 线程的情况下。这说明这个方向是对了的,但哪里肯定还存在问题。同样是检查刷盘的文件,虽然数量少了,但单个文件的大小跑到了 1GB 左右,这显然是不对的。于是让AI给我找原因,方向很明确:刷盘的总大小并没有减少。不仅如此已有的测试也无法完全通过。于是我打算先把测试修复再继续追性能,故事从这里才真正的开始
AI 帮我分析测试错误,发现是因为 dirty page 的生命周期的问题,在 page checkpoint 将 dirty page 删除后,有可能 iterator 或者 remote/sibling 地址还在使用,我想了想,确实存在这种可能,拿 iterator 来说,它会存放一个 Node 的副本,而这个 Node 上的所有 dirty page 都可能被 page checkpoint刷盘删除。AI 给出的方案是:delayed serialization,想法很简单:未持久化的 page 不会进入全局的 dirty page 池子,这样 page checkpoint 就无法造成 UAF,而对于这些为持久化的 page 在 page checkpoint 时使用一个临时的 Allocator 将他们合并后刷盘即可
delayed-serialization 这个方案的实现每一步都经过了人工 review 及时的纠正了实现偏离方案的情况,在方案完整实现后,前面提到的 UAF 的问题确实解决了,于是开始优化性能,这时发现因 page checkpoint 几乎是把整个 dirty page 池中的 page 都刷盘的,因此性能仍然很糟糕,于是 AI 给出了新的方案:增量刷盘。这个想法也很简单:每次 page checkpoint 只会将新增的 dirty page 刷盘,在刷盘后 ack 上次刷盘的地址,page checkpoint 就使用这个 ack 的地址用来判断哪些是 delta dirty page
增量刷盘这个方案修改的并不多,于是我让 AI 一步到位的实现了,但我对这个方案并不是很放心,因此我让 AI 先验证是否真的对 W4 有优化,经过一番测试和修改,确认了这个方案确实是有效的,p99 和 RocksDB 持平,ops 比 RocksDB 高 30%。随后开始将重心转移到测试上,很快就发现 gc_data/gc_blob 这两个测试会偶现崩溃,经过一番分析,AI 确定是因为之前依赖的 IntervalMap 的不变量已经不成立了。对于这种情况,最简单的办法是在实际刷盘的时候再分配 addr 即可,于是就有了 replace-interval 方案,因为当前的实现本身就有两套逻辑,其中一套完全是运行时的,因此对于这套来说,它的 addr 直接就是指针地址即可
很快,replace-interval 方案也落地了,测试也通过了。于是我回过头来看,发现其实有了 replace interval 之后,delayed-serialization 其实已经没有必要了,和 AI 讨论了下,AI 也确认 delayed-serialization 要解决的问题已经不存在了
当前实现已经不再依赖“中间态提前拿 durable addr”:
1. `Pool::alloc()` 分配的是 `alloc_local`,先进入 `Pool.pages`,不是 durable addr
- `src/map/buffer.rs`
2. `CheckpointTask::needs_flush()` 以 `is_local_ptr() || lsn > checkpoint_lsn` 判定刷盘
- `src/map/data.rs`
3. durable addr 在 flush 阶段统一 `pack_durable_addr + rewrite` 才生成
- `src/map/flush.rs`
但当前仍把 resident 作为 leaf 主路径,造成两类问题:
1. 运行时复杂度冗余
- leaf 双态(resident/addressable)让 checkpoint/evict/read-path 长期维护分叉逻辑
- `resident_seq` / `sealed_head` / resident owner 的维护成本高
2. addressable-only 合同未成文
- 如果直接撤 resident,而不先明确 `Pool.pages` 的清理闭包,存在“写入快于checkpoint清理”的积压风险
- `snapshot/done` 的 exact-remove 模型需要显式绑定到新主路径,不能依赖历史语义推断
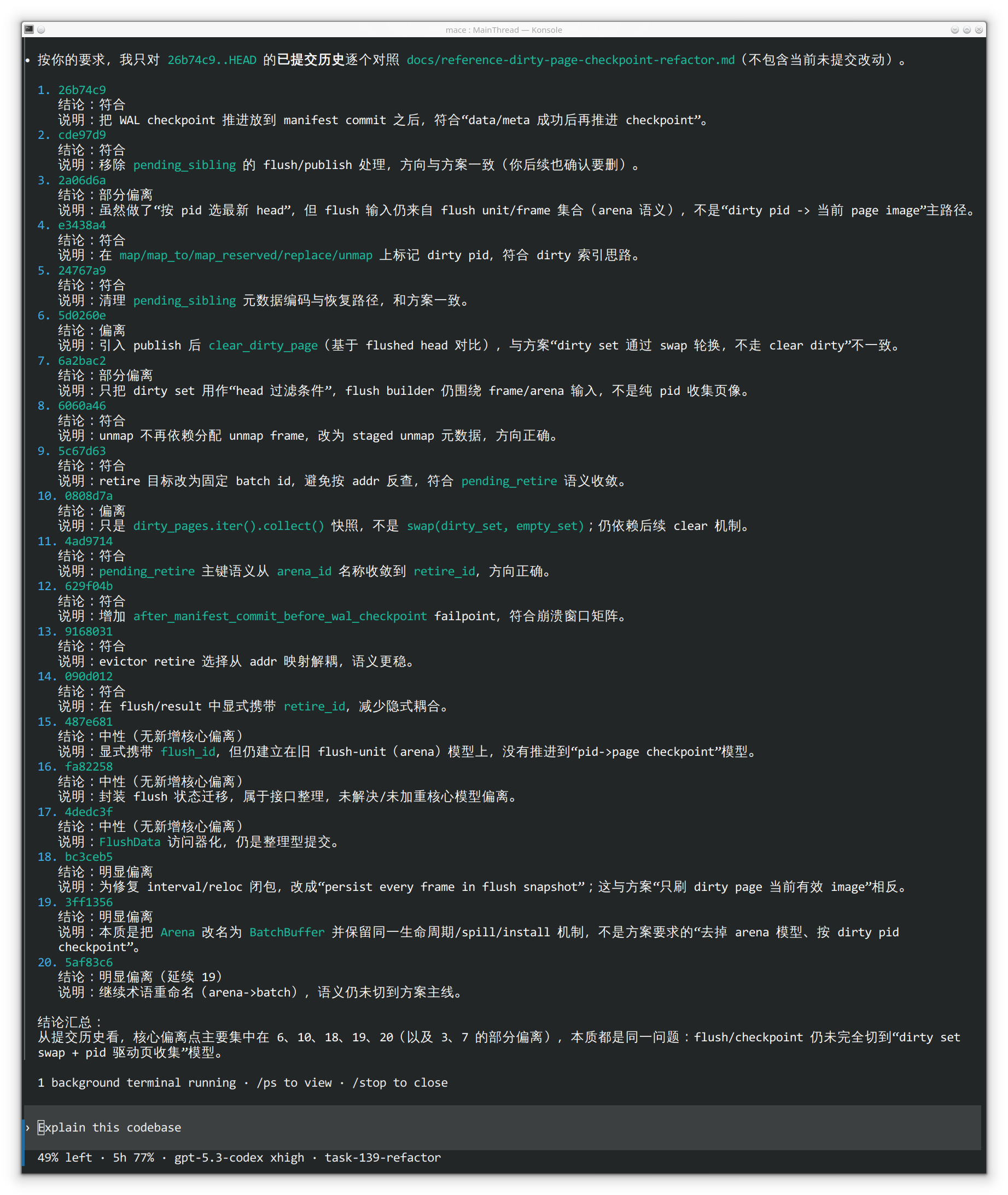
于是,又有了新的方案:no-resident 目的是去掉存内存的表示。我让 AI 完成新方案落地的同时,开始 review 之前 replace-interval 的实现,我只看了dirty page 刷盘的时候是如何做地址翻译的(即把内存指针映射成 addr),我震惊了, AI 的实现是对所有的 dirty page 新分配一个拷贝,然后修改 page header中的 addr 为持久化的地址。这显然是不可接受的,于是我停掉了 AI 对 no-resident 的落地,这时我感到非常的不安,或许一开始就走错了
我会到最初的 page checkpoint 的实现(我给 AI 擦屁股后的版本)仔细的进行测试和 review 发现这个方案本身是没有问题的,在纠正AI的实现后还存在的 UAF 这些问题,本质上的 checkpoint 没有考虑完备,在做 snapshot 前就将还可能被访问的(并发的)的 page 给回收了。在重新 review 代码后,我确定了,前面的路确实走错了!
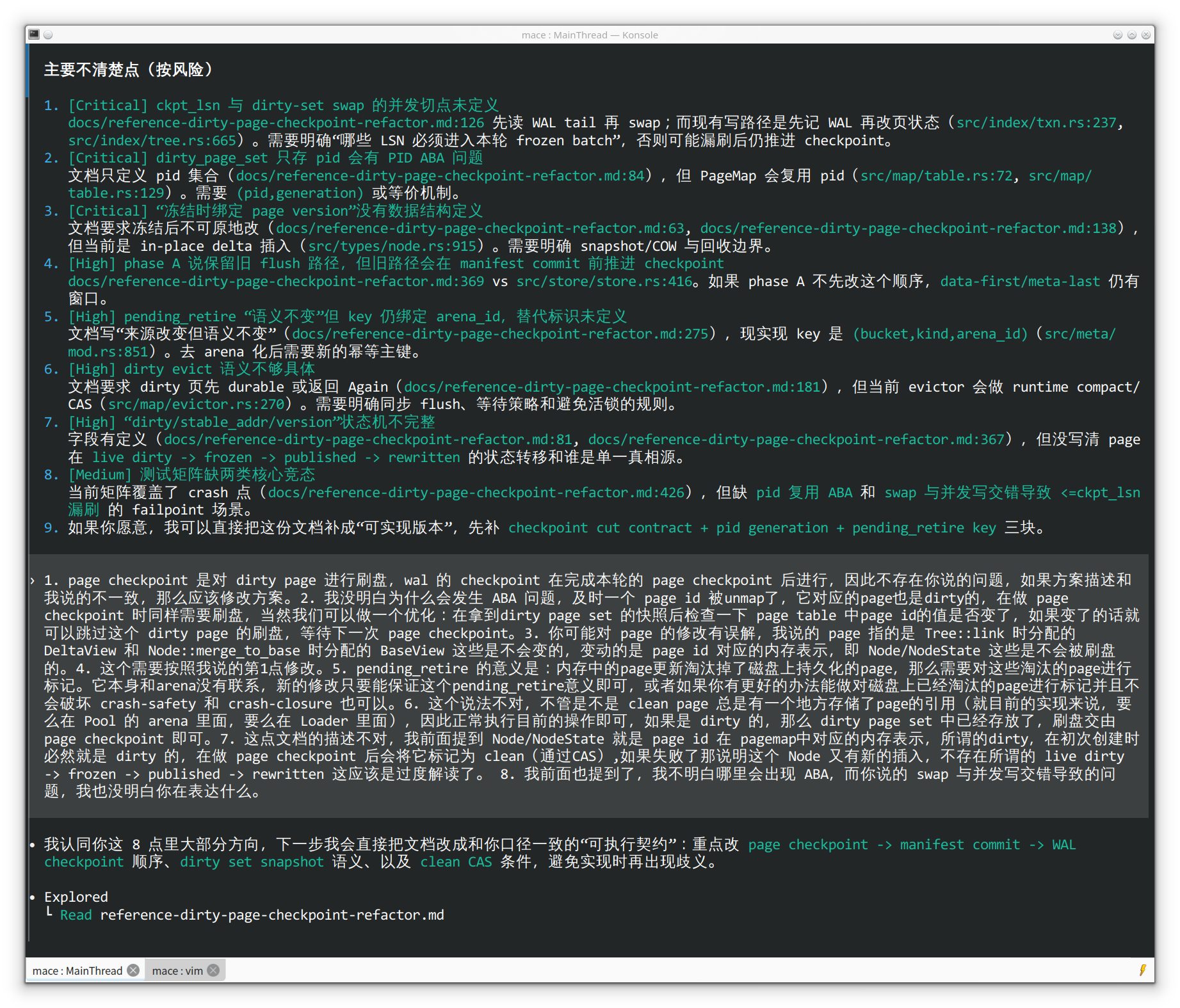
AI 发现了问题,它首先是做的是针对这个问题做修复,虽然你告诉它一定要找到 root cause 才能修改,AI 也只会在那条路上找 root cause 然后修复,它不会跳出来,从上层的视角来看这个问题:到底是上层的约束破坏导致的,还是方案本身就不可行导致,或者其他什么原因。于是你让它重新 review 一下方案,它会告诉的是方案的哪里没有“闭合” 这个问题如果不调整方案就没法解决,如果你信了它的话,可能就是上面故事的一个翻版
目前来看 context 受限应该是 AI 解决复杂问题不可靠的重要原因,这种情况下必须要人工介入给 AI 补充背景和提供方向,否则你指望 AI 帮你完成任务就需要消耗大量的时间和 token,AI 会不知疲倦的尝试所有可能的方向,也许在你耐心耗尽前能把任务完成。总的来说,AI 确实能做一部分事情,但前提是:你具有判断的能力并且你不能偷懒。因为 AI 不会替你负责,它只会给你说对不起。而所谓的 harness engineering 我并不认同,我认为这样会使得基础设施逐渐腐化,结果就是变成一坨狗屎,因为 LLM 本身并非“智能”,结果就是发展不可持续
以下是 AI 生成的方案文档
- 为了分离短命的page和需要持久化的 page reference-dirty-page-checkpoint-refactor.md
- 短命的 page 完全不放在 pool 中 delayed-serialization.md
- 每次刷盘只刷新增的 delta 部分 reference-incremental-metadata-flush.md
- 在刷盘时才分配持久化地址 replace-interval.md
- 回退 delayed-serialization 中引入的纯内存Node表示 no-resident.md