Background
我们都知道通常情况下一个线程里面的代码是顺序执行的,例如
void foo(int id)
{
for(int i = 0; i < 10; ++i) {
printf("routine %d\n", id);
}
}
int main() {
foo(1);
foo(2);
}
上面的代码必然是先打印出所有的1之后再打印出2。那么,我们能不能让1和2交替的打印呢?
稍作思考,觉得可行,因为你想啊,如果,这里的两个foo我们可以把它们分别放在不同的线程,然后两个线程分别打印1和2,这样不就行了吗。只不过调度的动作交给内核来完成,内核对线程的调度通常都是按照时间片来的1,时间片耗尽,内核把这个线程換出,然后执行继续另一个线程。我们完全可以向内核那样对1和2两个routine进行调度。但是,和内核不同的是,内核有各种硬件产生的中断来打断程序的执行,而用户空间并没这样的中断。不过值得庆幸的是信号可以看作是一个软件中断,它可以打断程序的执行,这样就使得我们有了进行调度的机会!
那么,开始我们的尝试。
Attempt
由于之前就写过栈切换的代码2,所以这次也就信手捏来,上代码
.text
.globl init_stack
.type init_stack,@function
.align 16
init_stack:
movq %rdi, %rax
leaq -0x40(%rax), %rax
movq %rsi, 0x30(%rax)
leaq quit(%rip), %rcx
movq %rcx, 0x38(%rax) // return
ret
quit:
xorq %rdi, %rdi
movq $60, %rax
syscall
.size init_stack,.-init_stack
.section .note.GNU-stack,"",%progbits
这次不用nasm是因为nasm不能直接使用rip寄存器。之前没有定义这样一个初始化函数,而是直接计算了routine在栈上的偏移量直接赋值的。这个函数的声明如下
extern "C" void* init_stack(void* stack, void* ctx_func);
有一点需要注意的是,x64的Linux下在rbp的下面会有一个固定大小为128字节的区域,叫做RED ZONE3。因此这个的stack的真实位置应该在这块区域的上方。
切换栈的代码和之前的差不多
.text
.globl switch_stack
.type switch_stack,@function
.align 16
switch_stack:
pushq %rbp
pushq %rbx
pushq %r15
pushq %r14
pushq %r13
pushq %r12
movq %rsp, (%rdi)
movq %rsi, %rsp
popq %r12
popq %r13
popq %r14
popq %r15
popq %rbx
popq %rbp
popq %r8 // return
/* Context pointer of ctx_function first argument */
movq %rdx, %rdi
jmp *%r8
.size switch_stack,.-switch_stack
.section .note.GNU-stack,"",%progbits
此函数的声明如下
extern "C" void* switch_stack(void** prev, void* next, void* self);
其中prev为当前的栈,next为要切换到的栈,self跳板函数的参数,表示当前的对象。
要说这两代码有没有问题,其实是有问题的4,当然你也可以用现成的context switch实现,比如Boost.Context, libaco,甚至内核里面的__switch_to。不过这里作为一个尝试,上面两锻代码就足够了。
好了,目前为止,我们的问题已经解决了一半了。接下来,我们需要一个“中断源“,也就是前面提到的信号。那么可以自发触发的信号当然就是定时器超时产生的咯,定时器的话我们还需要有足够的精度,至少需要精确到毫秒。有了这些条件,我们筛选出了使用struct itimerspec的timer_xxx系统调用,通过设置itimerspec的值,可以精确到纳秒。超时后产生SIGRTMIN实时信号。通过安装信号处理器,在信号处理器中进行调度。
现在,一切看起来是这么的美妙。但是,当我们遇到信号时总会有几个词语在脑中浮现:信号安全5,可重入6。而这些概念有着严格的要求,例如我们使用了单例(不幸的是确实使用了单例…)。当然,这只是一个尝试,如果能工作,那么我们下一步可以使用信号安全的代码。
下面是设置信号和定时器的代码:
void init_signal()
{
struct sigaction sa;
::memset(&sa, 0, sizeof(sa));
sa.sa_flags = SA_NODEFER;
sa.sa_sigaction = sched;
struct sigevent sigev;
::memset(&sigev, 0, sizeof(sigev));
sigev.sigev_notify = SIGEV_SIGNAL;
sigev.sigev_signo = SIGRTMIN;
sigev.sigev_value.sival_int = 0;
sigemptyset(&sa.sa_mask);
sigaction(SIGRTMIN, &sa, NULL);
timer_create(CLOCK_REALTIME, &sigev, &timer_);
}
这里有一点要注意,sa_flags通常使用时设置为SA_RESTART并且在sa_handler中提供信号处理器,但实际情况是,不管使用SA_RESTART还是SA_SIGINFO+sa_sigaction都会出现进入信号处理器后在也收不到信号。而这里的SA_NODEFER刚好解决了这个问题,有趣的是,使用这个选项后不管使用sa_handler还是sa_sigaction都能工作。
现在,两个最重要的条件已经准备好了,剩下的做一个简易的封装就行了,来看看结果,100ms切换一次:
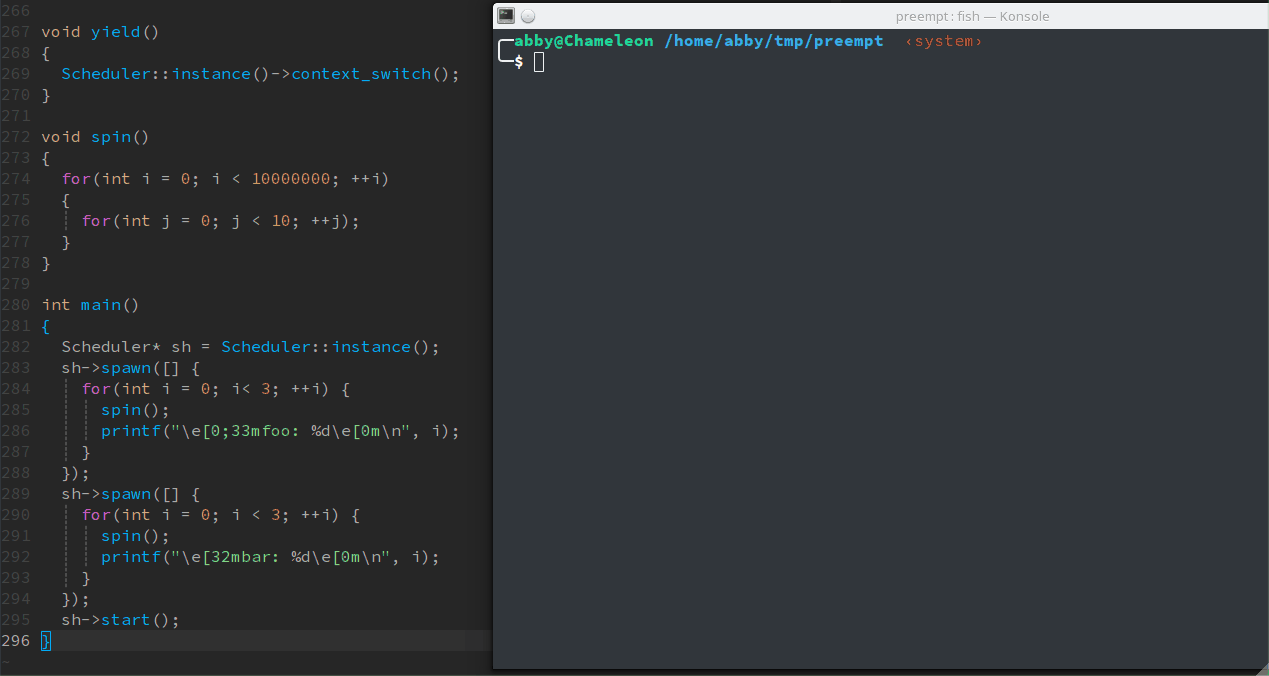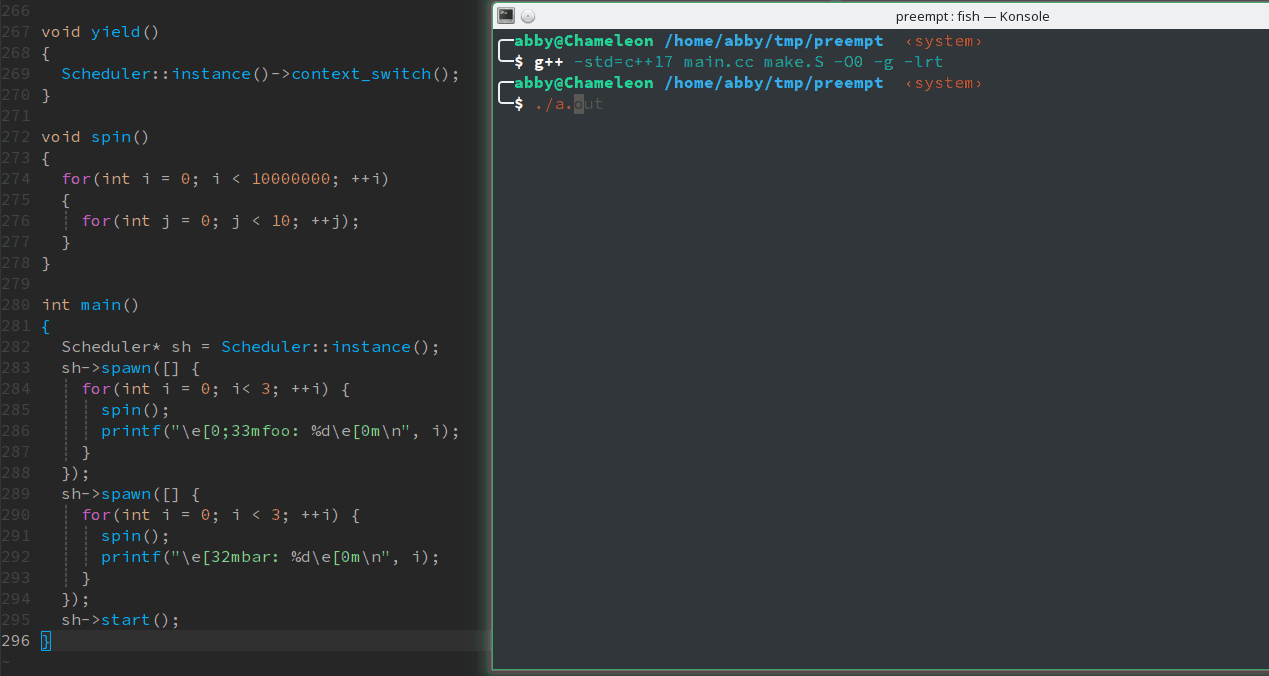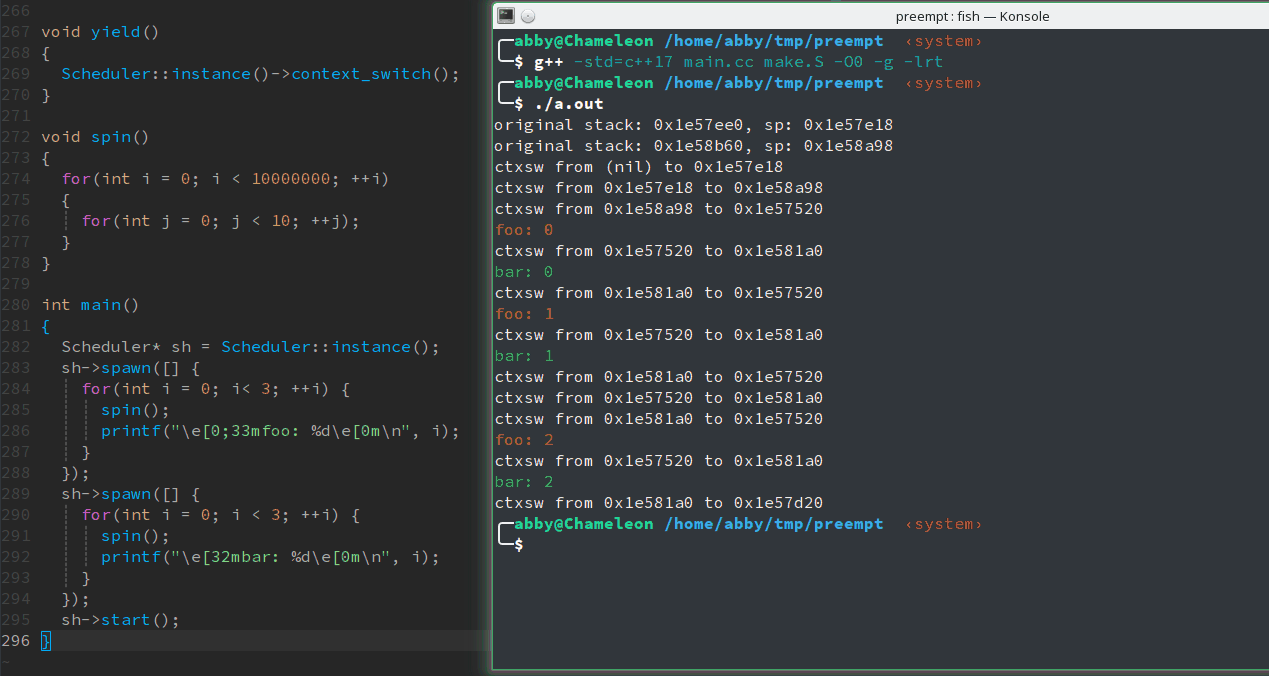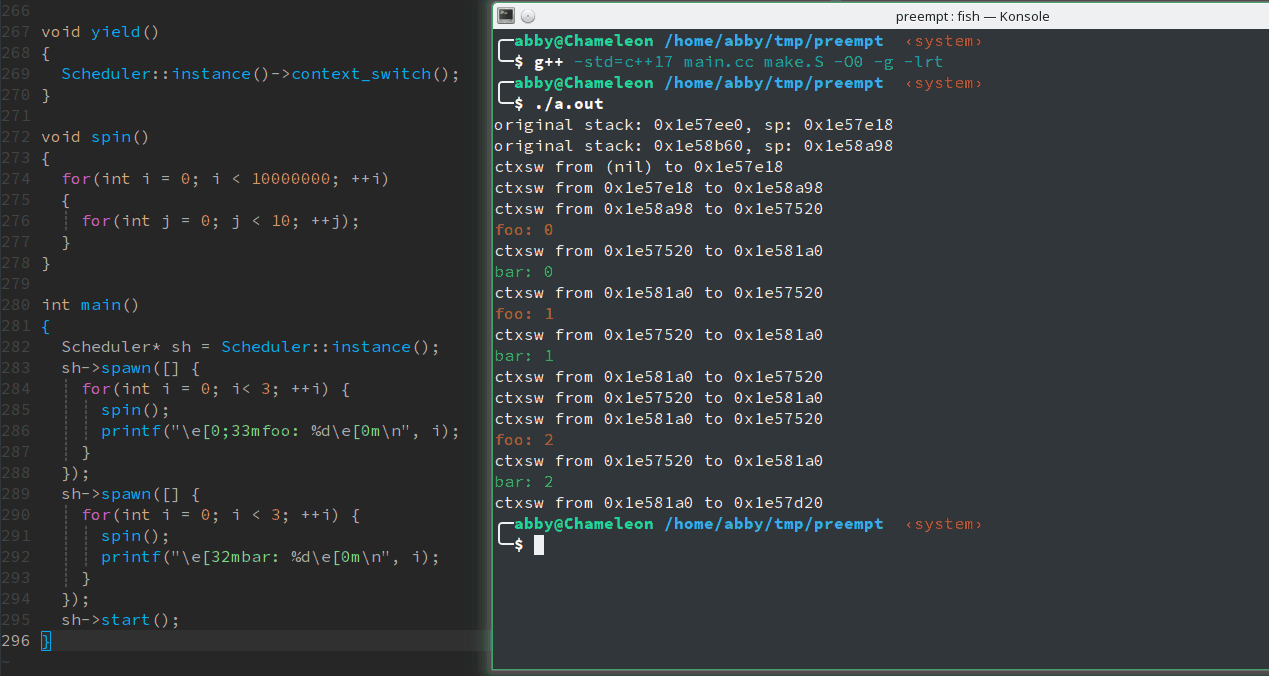
如你所见,确实按照我们的想法工作了。但是,仔细观察一下,似乎什么不对。
假设图中的三个routine分别是main,foo和bar。最初,从main切换到foo,然后立即从foo切换到了bar,再次从bar切换到foo时,目的地址是0x1e57520而最初foo的地址是0x1e57e18;同样再次从foo切换到bar时,目的地址是0x1e581a0而最初bar的地址是0x1e58a98;并且后续切换全是0x1e57520和0x1e581a0之间的切换!
后来,我们在信号处理函数中加入打印
static void context_switch(Context* from, Context* to)
{
from->set_status(Context::SLEEP);
to->set_statue(Context::RUNNING);
switch_stack(&from->sp, to->sp, to);
printf("back to handler\n");
}
再次运行后发现,当收到信号后发生栈切换,由于在信号设置时使用了SA_NODEFER选项,所以当在另一个routine里面时(信号处理函数并没有返回)会收到第二个信号,这时,程序跳转到上一次信号到达时运行到的地方,继续运行下一条指令。换句话说,这时,上一次的信号处理函数在本次收到信号时才返回!
这和直觉上不同,直觉上我们会以为信号处理函数永远不会返回,因为我们改变了下一条指令的地址。而事实上,内核会保存一份信号处理的上下文,记住了真正的下一条指令地址。
因为这个事实,我们之前所有的工作全都白费了,虽然我们忽略掉了其他一下影响实现的因素,唯独这个事实给了我们致命的一击!
或许你会说,上面图里面不是运行得好好的吗。但是,我们仔细观察,看看最后那个切换,其中0x1e57d20是第一次出现,而之后程序便退出了,再看看我们的init_stack,这里面写着在routine结束时调用_exit(0)退出。这便是问题所在,因为我们动态分配的Context还没有释放。但是,如果我们把_exit(0)换成exit(0)的话,内核就会回收内存了吧。是的,内核会回收内存,但是内核会发送信号杀死进程。原因是,我们还在信号处理函数中。下面是一个简单的模拟
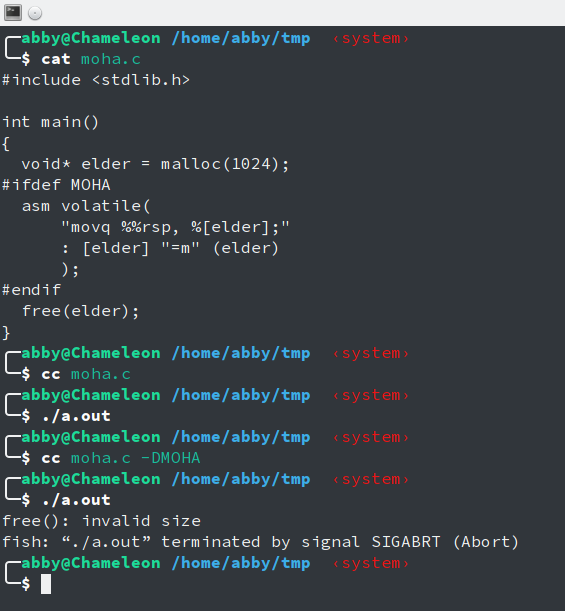
你可能会说,上面的代码完全是错误的。 是的,但是,在经过数个切换之后我们再也分不清我们分配的栈上到底存放这什么,并且,我们要想从信号出来函数中退出,必须要等到下一次信号的发生,而这时,可能还有很多个正在睡眠的routine,同样,内存不能即使的释放。
现在,我们来考虑前面影响实现却被忽略的几个因素:
1, 在context switch时,被其他信号断
2, 多线程问题
第一个问题可能会使得上下文更加混乱,比如在即将切换栈时,收到了另一个信号(比如SIGINT),这是程序仍然会切换到下一个routine,但是,下一次信号来的时候,我们却在处理上一个信号的逻辑里,这样就会导致不发生切换。如果信号是在栈上堆积的话还会导致栈溢出。
第二个问题依然是信号相关的,因为同一个进程中具体哪个线程收到信号完全是随机的。
一切的一切,就是因为我们突发奇想使用信号作为中断源。
既然我们失败了,那么别人是怎么做的呢?比如golang?
于是,我们写了一段测试代码:
package main
//void print(const char* data, int size) {
// asm volatile(
// "movq %rdi, %r8;"
// "movq %rsi, %r9;"
// "movq $1, %rdi;"
// "movq %r8, %rsi;"
// "movq %r9, %rdx;"
// "movq $1, %rax;"
// "syscall;"
// );
//}
//void loop(int id) {
// char data[2] = {id + '0', '\n'};
// int size = sizeof(data);
// unsigned long long i = 0;
// unsigned long long k = 0;
// long j = 0;
// for(i = 0; i < 1000000000; ++i) {
// k = i;
// if(j == 100000000) {
// print(data, size);
// j = 0;
// k = 0;
// }
// ++j;
// }
//}
import "C"
import (
"runtime"
"sync"
)
func foo(id int, wg *sync.WaitGroup) {
C.loop(C.int(id))
wg.Done()
}
func main() {
runtime.GOMAXPROCS(1)
wg := sync.WaitGroup{}
wg.Add(2)
go foo(1, &wg)
foo(2, &wg)
wg.Wait()
}
上面的代码中,我们通过cgo自行封装了输出的实现,目的是不给golang调度器进行调度的机会。我们期待这运行结果是:打印出所有的1后再打印出2, 或者反过来,不会出现交替打印。 然而,事与愿违,上面的代码的输出是交替打印的!
随后,使用gdb调试发现:
(gdb) run
Starting program: /root/go/bin/main
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
[New Thread 0x7ffff55e0700 (LWP 3552)]
[New Thread 0x7ffff4ddf700 (LWP 3553)]
[New Thread 0x7ffff45de700 (LWP 3554)]
Breakpoint 1, loop (id=2) at /root/go/bin/main.go:21
21 // print(data, size);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7_6.3.x86_64
(gdb) i thread
Id Target Id Frame
4 Thread 0x7ffff45de700 (LWP 3554) "main" 0x00007ffff78efe71 in clone () from /lib64/libc.so.6
3 Thread 0x7ffff4ddf700 (LWP 3553) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
2 Thread 0x7ffff55e0700 (LWP 3552) "main" runtime.usleep () at /root/go/src/runtime/sys_linux_amd64.s:131
* 1 Thread 0x7ffff7feb740 (LWP 3548) "main" loop (id=2) at /root/go/bin/main.go:21
(gdb) continue
Continuing.
[Switching to Thread 0x7ffff4ddf700 (LWP 3553)]
Breakpoint 1, loop (id=1) at /root/go/bin/main.go:21
21 // print(data, size);
(gdb) i thread
Id Target Id Frame
4 Thread 0x7ffff45de700 (LWP 3554) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
* 3 Thread 0x7ffff4ddf700 (LWP 3553) "main" loop (id=1) at /root/go/bin/main.go:21
2 Thread 0x7ffff55e0700 (LWP 3552) "main" runtime.usleep () at /root/go/src/runtime/sys_linux_amd64.s:131
1 Thread 0x7ffff7feb740 (LWP 3548) "main" loop (id=<optimized out>) at /root/go/bin/main.go:24
(gdb)
可以看到,这两个routine被分配到了不同的线程,即使我们的机器是单核的。仔细看会发现,达到第一个断点时仅有一个线程在跑loop函数,而后面线程3也开始跑loop函数了,这就是很明显的work steal了,这里交替打印实际上是内核的调度。
随后,我们重写一个foo2函数,使用fmt.Println做打印:
Breakpoint 1, main.foo2 (id=2, wg=0xc0000160e0) at /root/go/bin/main.go:44
44 fmt.Println(id)
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7_6.3.x86_64
(gdb) i thread
Id Target Id Frame
4 Thread 0x7ffff45de700 (LWP 3760) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
3 Thread 0x7ffff4ddf700 (LWP 3759) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
2 Thread 0x7ffff55e0700 (LWP 3758) "main" runtime.usleep () at /root/go/src/runtime/sys_linux_amd64.s:131
* 1 Thread 0x7ffff7feb740 (LWP 3754) "main" main.foo2 (id=2, wg=0xc0000160e0) at /root/go/bin/main.go:44
(gdb) continue
Continuing.
Breakpoint 1, main.foo2 (id=1, wg=0xc0000160e0) at /root/go/bin/main.go:44
44 fmt.Println(id)
(gdb) i thread
Id Target Id Frame
4 Thread 0x7ffff45de700 (LWP 3760) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
3 Thread 0x7ffff4ddf700 (LWP 3759) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
2 Thread 0x7ffff55e0700 (LWP 3758) "main" runtime.usleep () at /root/go/src/runtime/sys_linux_amd64.s:131
* 1 Thread 0x7ffff7feb740 (LWP 3754) "main" main.foo2 (id=1, wg=0xc0000160e0) at /root/go/bin/main.go:44
(gdb) continue
Continuing.
2
Breakpoint 1, main.foo2 (id=2, wg=0xc0000160e0) at /root/go/bin/main.go:44
44 fmt.Println(id)
(gdb) i thread
Id Target Id Frame
4 Thread 0x7ffff45de700 (LWP 3760) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
3 Thread 0x7ffff4ddf700 (LWP 3759) "main" runtime.futex () at /root/go/src/runtime/sys_linux_amd64.s:536
2 Thread 0x7ffff55e0700 (LWP 3758) "main" runtime.usleep () at /root/go/src/runtime/sys_linux_amd64.s:131
* 1 Thread 0x7ffff7feb740 (LWP 3754) "main" main.foo2 (id=2, wg=0xc0000160e0) at /root/go/bin/main.go:44
(gdb) continue
Continuing.
1
Breakpoint 1, main.foo2 (id=1, wg=0xc0000160e0) at /root/go/bin/main.go:44
44 fmt.Println(id)
可以看到,所有的打印都在线程1中,id从2变到1,又从1变到2,明显是出现了栈切换。而且很明显golang里面hook了系统的输出函数,在这个hook中进行了调度,类似于:
ssize_t write(int fd, void* buf, size_t size)
{
sched(); // 判断是否需要调度,比如时间片耗尽
syscall(SYS_write, fd, buf, size);
}
所以,即使是golang也不是抢占式调度的7。
Conclusion
It’s impossible to implement a preemptive scheduler in userspace!
或许,我们可以写驱动?
Reference
1, 目前内核所用的CFS(Completely Fair Scheduler)并不是按照时间片进行调度的,而是使用了优先级
2, 一个最小化协程的实现
3, RED ZONE)
4, libaco issue: 我就想问问有啥区别?
5, Asynchronous Signal Safety
6, Reentrancy)
7, runtime: golang scheduler is not preemptive