swisstable是在几年前的CppCon视频上看到的,这是abseil库中实现的flat_hash_set和flat_hash_map的基础,它将Hash值的特征提取出来,并分为若干个组,利用SIMD进行过滤,以此实现快速查找
结构
以下是swiss table的结构
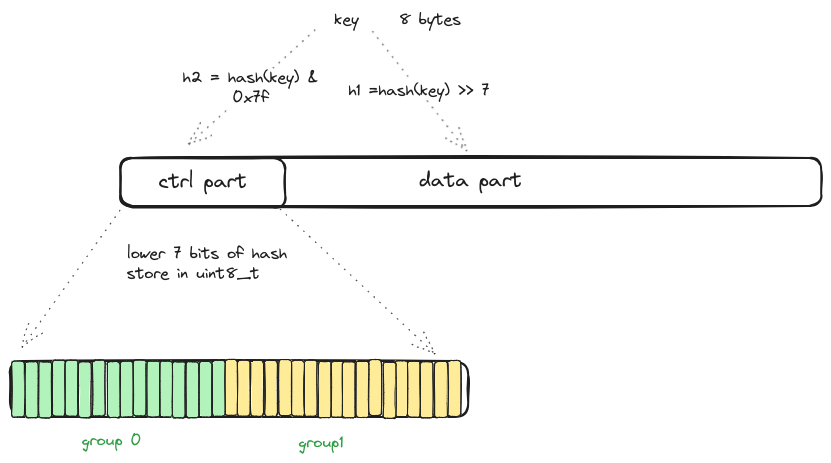
在swisstable中,将key的hash值拆成了两个部分:H1和H2,其中
H2是key在ctrl part中的偏移
H1模上group数量则得到key在data part中的位置,H1模上group数量则得到key在ctrl part中的的分组
这里的group大小是固定的16各字节,刚好是一个SSE2操作的大小
ctrl 是一个8位的数,其中低7位为H2,而最高位则用来做特殊判断,几个特殊的ctrl值是
- -128 =>
1000 0000表示ctrl为空,即没写入过数据,初始化ctrl块时设置的默认值 - -2 =>
1111 1110表示ctrl已经被删除了 - -1 =>
1111 1111作为结束标志sentinel
当设置了h2时,最高为必然为0
查找
对于hashset来说,查找是几个操作中最重要的一个,不管是insert还是delete都依赖于查找,下面查找过程:
代码如下
bool find(const Key &key)
{
uint64_t offset;
auto hash = hash_fn(key);
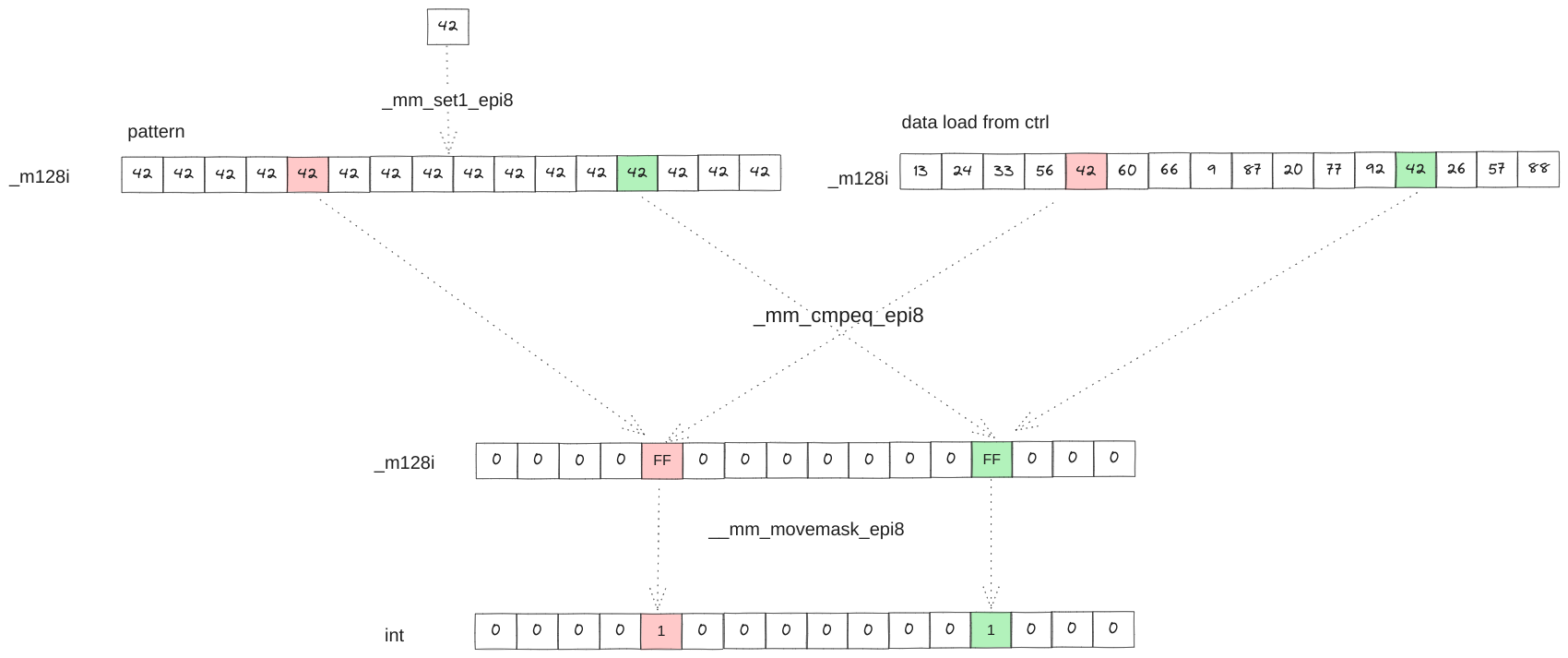
auto pattern = _mm_set1_epi8(H2(hash)); // 扩展h2到128位 (a
auto group = H1(hash) % groups_; // 找到h2所在group,以及key在data_中的起始位置
matcher m { 0 }; // 重载operator++的类
while (true) {
group g { ctrl_ + group * 16 }; // 从group起始读取128位
m = g.match(pattern); // 和pattern比较得到128位值,其中位为1的位即key所在起始位置的偏移 (b
while (m) { // 当m中的位不全为0时
offset = group * 16 + m.index(); // key的偏移等于起始位置group * 16加上偏移 (c
if (likely(data_[offset] == key)) // hash可能冲突,因此需要比较key
return true;
++m; // 去掉低位的1
}
if (likely(g.match_empty())) // 如果读取的是128位中有结束标志,则结束循环
return false;
group = (group + 1) % groups_; // 前往下一个组,
}
}
(a 这里使用了指令_mm_set1_epi8,作用是将输入的8位扩展16次,变成128位,每字节都相同
(b 这里使用了两个SSE2指令
- __m128i _mm_cmpeq_epi8 (__m128i a, __m128i b) 按位比较a和b,如果相同则返回值对应的位置为0xff否则置为0
- int _mm_movemask_epi8 (__m128i a) 将128位的a映射到返回值的低16位,每8bit映射一次,刚好将上面为0xff的映射为1
(c m.index() 即返回从低到高位1的下标,使用指令 ctz (__builtin_ctz)即count trailing zero
以上三个流程如下图
需要注意的是,在初始化ctrl时会多分配一个字节用来做结束标记,另外内存是16字节对齐的,这样使用SIMD可以对齐加载
优化
根据以上的描述,大概可以写一个使用SIMD加持的hashset了,接下来是对上面描述的hashset实现的一些优化
内存对齐
使用SIMD指令加载ctrl数据时如果不对齐可能导致多次内存访问,影响性能,因此可以使用posix_memalign来分配内存
这样就可以使用 _mm_load_128i一次加载16字节内存
预取
swisstable是开放寻址模式,所有数据都在一块连续的内存上,根据局部性原理,可以对ctrl和data进行预取
__builtin_prefetch(ctrl, 0, 1);
__builtin_prefetch(ctrl + offset, 0, 3);
__builtin_prefetch(data + offset, 0, 3);
其中offset对ctrl来说是group的起始,对data来说是key的起始,第一个参数是要预取的内存地址,第二参数只有0和1两个值,其中0表示读预取,1表示写预取,第三个参数表示局部性,范围是0到3,1表示在一次操作后可能就不在缓存中,3表示数据有高度的时间局部性,应该被放置在各级缓存中,2则介于两者之间
结构优化
以上的结构存在的问题:
- 当插入时,相同h2的key总是按照插入的顺序排列在
group中,因此在find时,需要从group的起始位置开始顺序往后挨个比较key,因为h2只有7个字节,因此当key较多时,这种情况会变得很严重甚至会跨过很多个group
针对以上问题,可以将寻找h2和key所在的group改为寻找h2和key的起始pos,即将H1(hash) % groups改为H1(hash) % capacity
这样的结果就是pos相比于group更加分散,pos就是group的起始位置,更有可能pos处就是要查找的key,因为capacity是groups的16倍,这个修改把它叫做float group
当这样修改后,会出现一个问题,即:pos > capacity - 16时,使用SSE加载16字节的数据会导致读取到ctrl外部的数据,我们期望这种情况下SSE可以round到ctrl的最前面,即SSE所需的数据分成了两个部分:
- 一部分在
ctrl的末尾
- 另一部分在
ctrl的开头
但SSE并不会转弯,因此这里需要在分配ctrl内存时额外分配一些字节,并在每次插入时判断pos是否小于16(极端情况是查找时pos刚好在ctrl的最后一个字节,因此需要使用ctrl的前15个字节)将ctrl头部的数据复制到额外分配的几个字节中,代码如下:
if (pos < 16)
ctr[pos + 1 + cap_] = h2
对比
& abby @ chaos in ~/swiss/build (master)
λ ./bench
----------- int insert ------------
std::unordered_set => 164.099074ms
absl::flat_hash_set => 21.567153ms
swiss => 21.538882ms
robin_hood_hash => 31.012937ms
----------- int search ------------
std::unordered_set => 40.907672ms
absl::flat_hash_set => 6.038115ms
swiss => 5.176989ms
robin_hood_hash => 16.223713ms
- flat_hash_set https://github.com/abseil/abseil-cpp/blob/master/absl/container/flat_hash_set.h
- swiss https://github.com/abbycin/tools/blob/master/swisstable/swisstable.h
- robin_hood_hash https://github.com/martinus/robin-hood-hashing.git
总结
提取特征再分组这个思路在leveldb里面也有,用在SSTable结构里面,大约是前缀相同的词每16个一组,这应该是一种常见的优化技巧 对于性能优化,使用SIMD是一个方向,比如这里用到的SSE2指令,如果不支持,那做分组也不会有太大提升;对于数组结构利用空间局部性适当的进行预取可以提升些许性能;对于最后结构的优化要平衡trade off,因为hash表查询一般多有插入,因此可以牺牲部分插入性能来提升查询性能